Uptime improvements and monitoring
I helped increase the uptime of various environments.
More information
Uptime is a bit of a touchy subject. On one end, people seem to obsess over having zero downtime and make development much harder than it should be (though this is understandable for certain services), on the other people don't necessarily care as long as it doesn't impact themselves personally.
In my mind, doing all of the "easy" things to achieve good uptime is a no-brainer, even in regards to something like development, testing and staging environments - after all, you should make sure that QA have a pleasant experience as well.
What I did
After introducing containers to many of the projects in the org, I also added uptime checks within the containers themselves, so that they'd know that they might need to restart and report failure in case of applications crashing in the containers. Sometimes you encounter such setups, such as when you have Tomcat running inside of the container process, but the application inside of it can stop working without Tomcat itself going down.
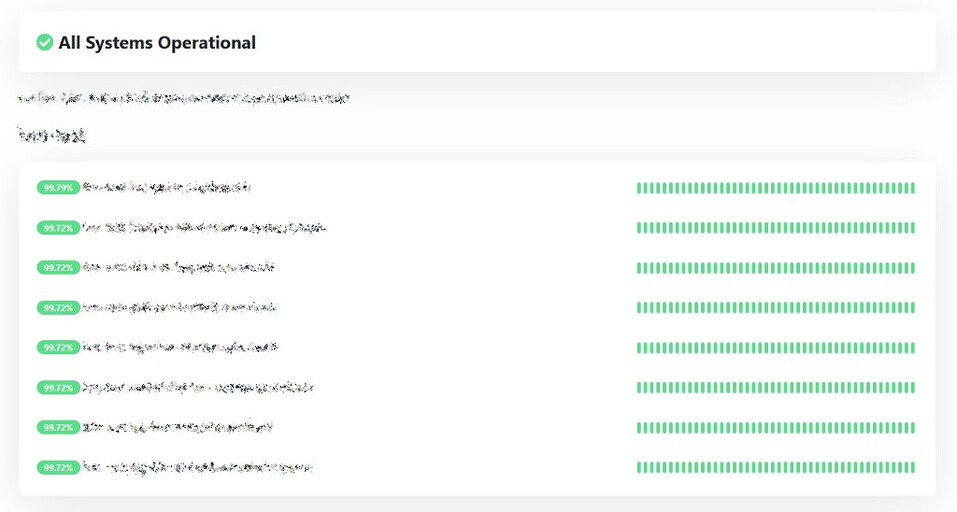
However, I felt like external monitoring is also necessary. Well, even on-prem you can have a server or some resources within your cluster set aside for monitoring whether all of your services are up, especially when you have dozens of those. For this, I implemented Uptime Kuma, a really nice self-hosted status page. I also integrated it with Slack so that we'd get timely notifications about any issues, as well as reminders about TLS certificate expiry.
What I learnt
To me, this project was fully worth it. Uptime for even development environments went well above 99%, QA never needed to be the first ones to bring the bad news about something going down to the developers, TLS expiry could no longer sneak up to anyone and people could just deploy things with the confidence that they'll be notified of issues should any arise, as opposed to having to babysit Tomcat or similar solutions themselves.